23:10 09/01/26
POPL 2009
行ってきました。MS Research 多いなーというのと、
まあ当たり前ですが並列並行系多いなーというのが全体的な感想。
以下印象に残ったものだけメモ。
1日目
個人的には
"Flexible types: Robust type inference for first-class polymorphism"
が面白かったです。First-class polymorphism っていうのは、
「多相関数」を関数の引数にしたり返したりとファーストクラスオブジェクトとして扱えること。
apply_to_int_and_bool f = (f 10, f True)
id x = x
main = print (apply_to_int_and_bool id)
というコードは、引数 f には Int->Int という型を付けるのも Bool->Bool
という型を付けるのもどっちもダメで、forall a. a -> a という多相的な型を付けてやらないと型チェック通らない。
ところが、"普通の" ML や Haskell は引数にこういう型をつけることはできません。
関数はファーストクラスでも多相関数はファーストクラスではなくなっています。
ghc なら -XRankNTypes とか付けて、あと apply_to_int_and_bool の型を手で書いてやれば使えます。
何故ファーストクラスの多相関数が無かったかというと、理由のひとつとして、これを考えると型推論が難しい、
というか、完全な型推論は不可能(チューリングマシンの停止問題が計算不可能的な意味で)というのがあります。
ghc のように、ある程度人間が手で型を書くことを強制しないと原理的に無理なのです。
そこでここに、「人間が手で型注釈しなきゃいけない範囲をできるだけ少なくできる型推論アルゴリズム」
を見つけよう、という競争が巻き起こります。ここ数年いろいろな提案がなされてきました。
- MLF : "Flexible Type" と "Rigid Type"
という新しい種類の型を導入することで限界まで注釈の必要性を減らすシステム。
- HML : この論文。"Flexible Type" だけを使うことにしてみるシステム。
- FPH : "Boxy Type" という型を導入。ところどころ注釈が必要。今の ghc はこれだった気がする。
- HMF : 新しい種類の型は使わず推論側だけで頑張れるところまで頑張ってみるシステム。ところどころ注釈が必要。
この論文のは、MLFは難しいので、もう少し簡単にしたところに上手い落としどころがあるんじゃない?っていう提案で、
「関数定義の多相型引数には型注釈が必要&あとは不要、と、注釈の必要な箇所が明確」
「多相型とFlexible型の対応が、単相型と多相型の対応とよく似た感じになっていてちょっと綺麗」
「型推論もMLFほど大変でない」
という特徴があるらしいのですが、確かに上手いこと落ち着いていて、
そろそろこの辺で決定版ということになるんじゃないかなー、と素人目には思えてしまうくらいでした。
"SPEED: Precise and Efficient Static Estimation of Program Computational Complexity"
は関数の定義を解析して計算量のオーダーを出すシステムを頑張ったらしい。
STLのアルゴリズムで色々実際に試していたらしいのだけど、具体的にどのくらいまで解析できたのだろう。
(ちゃんと聞いてなかった。)
パネルセッションの "Grand Challenges in Programming Languages" は、
オフィシャルなまとめページ ができてました。
we can have the most impact not in language design per se but in architecture
の辺りが一番印象に残ってます、というかなるほどと思いました。
2日目
招待講演 "Wild Control Operators" が楽しかったです。
いわゆる自然言語と継続の話(これ (PDF) とか)なんですけど、compositional な意味論を与えようとすると継続が必要になってしまう、
という辺りがやっとわかってきました。あと、
プログラミング言語でも今のところ使われていないような怪しげな control operator
を持ち出さないと意味を与えられない用語があったりして、
そういうのこそが自然言語だと"自然"に書けるのの一因じゃなかろうかとか、
逆に、そういうのをプログラミング言語の側に持ってくるとどういう使い方ができるだろうか、等々。
次のセッションもどれも楽しみにしていた発表でした。
"Lazy Evaluation and Delimited Control" は Call-by-Need のラムダ計算を、
操作的意味論を元に、サンクのような破壊的操作を使わずに Call-by-Value + 限定継続 で表現するといった話。
継続ももちろん副作用だし破壊的といえばそうなんですが、あまりそう露骨な破壊的操作は避ける感じで。
"Bidirectionalization for Free!" は、ちょっと前 に触れた論文。
"The Third Homomorphism Theorem on Trees: Downward & Upward Lead to Divide-and-Conquer"
はある種のツリー処理アルゴリズムを自動並列化するよという話で、Zipper を使うことで「分割統治」のやり方を整理。
Zipper 大好き人間こと自分のツボに結構入った。
"Copy-on-Write in the PHP Language" は、
「変数間の代入をすると値コピーになるセマンティクスの配列をうかつに copy-on-write で共有すると、
配列要素に対する参照を取られたときに悲惨なことになるぜ」
という話で、悲惨なことにならないように頑張って copy-on-write もどきにしたものがちゃんと「正し」くなることを、
PHPの意味論を定義してbisimulationを示して証明したというもの。
その悲惨なことになる問題はC++でも問題になってましたーという話を著者の方々としてきたりしました。
Program Chair's report で特に面白かったのが、今年は著者に論文submit時にアンケートで
「定理の自動証明系を使いましたか?(この回答が採択に影響することはありません)」
と尋ねてみた、というお話。トータル159論文のうち、somehow used: 30、fully verified: 12、だったらしい。
足すと4分の1は超えている計算ですね。自分は使いたいなーと思いつつ全然使い始めてないので今年こそは…。
「ところで "この回答が採択に影響することはありません" とは、もちろん、
査読/採択の判断基準に使うことはないという意味でした。しかし、そういう意味ではなく、
統計的な意味で何らかの影響、相関は果たしてあったでしょうか?」
→ 採択論文36本中、somehow used: 5, fully verified: 2。あれ?w
あと、そうだ、Most Influential POPL Paper Award は
Andrew C. Myers, "JFlow: Practical mostly-static information flow control" だそうな。
3日目
"State-Dependent Representation Independence" を聞くちょっと前にメールチェックしていたら
Types-ML で すごいアナウンス
が流れてて危うくコーヒー吹くところでした。
ref があることで始めて生まれる等価な挙動の別実装の例等々、発表はわかりやすかったです。
"Modeling Abstract Types in Modules with Open Existential Types" は、
MLとかの「モジュール」の理論的な対応物として使われる Existential Type を綺麗にしたというもの。
いやこれは確かに綺麗だ。
Existential Type だと、いったんレコードを普通に作ってから pack
というプリミティブで外向けに隠したい/抽象化したい部分だけ隠す、という形でモジュールを作るんですけど、
Open Existential Type では、先に抽象化したい型に割り振る型変数を決めて、それを使ってモジュールを記述、
みたいな書き方ができる。モジュールを使う側(unpack)も、似たような、
型変数の導入タイミングを変えられる変更が加わってます。
ほか
会場にSpringerとかが特別価格で本を売りに来ていたりするんですが、パラパラ立ち読みしてみたところ、
"Semantics with Applications"
が面白そうでした。2007年に新版が出ているみたい。
会場特別価格より Amazon.co.jp の方が安くてどうしようかと思いました。
プログラミング言語の意味論の入門書で、操作的・表示的・公理的意味論それぞれの説明と、
それぞれどういう応用に使われるかを解説していく形のようです。
意味論の基本的なところを押さえておきたい、という人に良さそうな気がします。
あと、今春発売の "Pattern Calculus"
というのもかなり興味をひかれるものがあります。買おうかな。
と、そんなところでした。
実況しようかと思ったけど途中でフェードアウトしたいい加減twitterログ
は多分役に立たないと思うけど一応晒しておくテスト。
※追記: 住井さんによるリンク集
09:01 09/01/17
論文ファイブ
"DO++: 昨年の論文をふりかえる"、
"Leo's Chronicle: Top 5 Database Research Topics in 2008"
が面白かったので真似してみようと思います。
2008年に発表された論文で個人的に面白いなと思ったもの5つ。
評価基準は「most influential to 俺」。
たぶん、分野全体としてみると特にそこまで新しくもなかったり時代に影響してなかったりもするかもですが、
とにかく、純粋に自分にとって新しかったもの、自分の考え方に影響したなーと思うものを挙げます。
F. Cantin, et al. "Computing Convex Hulls by Automaton Iteration", CIAA 2008
[PDF]
前に紹介(16:36 08/07/27)した論文です。
自然数や実数の無限集合、あるいは実数のペア/N個組の無限集合(要はN次元空間内の点集合)
などなどをオートマトンで表現する、というアプローチがありまして、
要はおおざっぱに言うと、ビット列に対する正規表現を、それにマッチする数全体の集合と見なすわけですね。
対象が無限集合であっても、オートマトンという有限の記号で表現できているので、
集合の共通部分を取ったり合併したりという集合演算は有限の時間できっちり計算できます。
…というのが背景。
この論文は、そういう集合操作のひとつとして、
凸包(指定された集合の点を全て含むような一番小さい凸図形)を求められると便利なので求めてみた、
というお話です。なんで便利なのか等については省略。
何が印象に残ったかというと、その凸包を求めるアルゴリズムがとても格好良かった!
凸包って、オートマトンや無限集合なんか持ち出さなくても、普通に幾何的なアルゴリズムで求められるものなんですよ。
ただ、それは少なくとも僕にとっては結構理解するのが難しいアルゴリズムで、恥ずかしながら、
2次元凸包の求め方は覚えられても3次元以上をいまだにしっかり理解てきていません。
一方で、この論文のオートマトンで頑張る方式は、
「無限」を表現できるという利点をフル活用して、
何次元だろうがものすごく直感的な構成になってて恐ろしくわかりやすかった。
もちろん、既存の方法に比べて効率は比べものにならないくらい効率は悪いですし、
そもそも実は停止性の保証されてないセミアルゴリズムだったりしますし、
実装もオートマトンの扱いを全部頑張って作らなければいけないことを考えると明らかに大変です。
幾何的な意味で凸包が欲しいときに便利なことは、少なくとも現時点では何一つない。
ただ、もし、こういう「無限」を扱うライブラリがきっちり整備されて、
普通の言語に当たり前のように標準搭載される時代が仮に来たらどうでしょう。
これまであまり考えたことがなかったけれど、
無限の世界に話を持っていくと劇的に話がシンプルになる問題は、
きっと凸包に限らず結構いろんなところに転がっているんじゃないかと思う。
遅延評価だと無限リストが使えて便利という話や、
RealLib みたいな話もある意味そういう方向でしょうし。
さてさて。
J. Voigtländer "Bidirectionalization for Free!", POPL 2009
[PDF]
SQL の View みたいなのをイメージすればいいのかな。ちょっと違うかな。
たとえばリストの偶数番目の要素だけ取り出してそのリストを返す関数 (take_even) があったとしましょう。
言ってみればこれは元のリストの一部分を取り出したviewを作る関数です。
viewに対してなんかのリスト操作、たとえばreverseをしたときに、
そのreverse結果を、元々のリストに反映したい。Haskell で。
lst = [1, 2, 3, 4]
view = take_even lst -- [1, 3]
view' = reverse view -- [3, 1]
lst' = commit_take_even lst view' -- [3, 2, 1, 4]
この場合、commit_take_even は take_even の逆みたいなことをすればよくて、
つまり、第二引数のリストを偶数番目のところに埋めればよいです。
問題はどうやって commit_take_even を実装するか。
(1) 頑張って手で書く (2) Haskellをあきらめてtake_evenを定義すると同時に逆演算も定義されるかっこいい言語を使う
(3) take_evenの定義から逆演算を生成するようなメタプログラムをテンプレートとか駆使して書く。
もちろん 1 では研究にならないですね。2 や 3 はどうでしょう。
これは結構いろいろこっち方面の過去の研究がなされています。が、この論文のアプローチはひと味違います。
(4) take_evenのような関数を受け取って逆演算を返す関数を普通のHaskellで書く。
メタプログラミングしない。take_evenの定義は一切見ない。
ただ値として関数を受け取ってそっからその逆演算を作り出すマジック。
take_even を受けとる、と言われても、
関数を受け取ってもできることはその関数に引数渡して実行するしかできることはありません。
しかし、型からプログラムを当てる話 の応用で、
引数渡して実行するだけで逆演算を作るための情報は全部取り出せるのです。
言われてみればなるほどすぎて、やられた!!という感じ。
著者の方は最近こういうパラメトリシティを使った小粋な応用をいくつも発表されてて、どれも面白いです。要注目。
C. McBride "Clowns to the Left of me, Jokers to the Right", POPL 2008
[PDF]
これも前に少し触れた(10:08 07/12/12)もの。
中身は、map や fold の外部イテレータ版というかなんというか、
mapしてる途中で止まってるような状態を表すデータ構造を、
元のコンテナの型定義から自動的に作りまっせという話。Zipper の強化バージョン。
それはそれで面白いんですが、この論文は、特に締めの言葉が好きでした。
すでに一度引用してますけれどもう一回。
But if there is a message for programmers and programming language designers, it is this: the miserablist position that types exist only to police errors is thankfully no longer sustainable, once we start writing programs like this. By permitting calculations of types and from types, we discover what programs we can have, just for the price of structuring our data. What joy!
「型 = メタデータ」というバズワードを流行らせようぜ、と最近ときどき口走っている私なのですが、
こう考えが固まってきたのはこの一節を読んでからだったように思います。
「型」が「コンパイラがプログラマを怒るためだけのもの」だった時代はとっくに過ぎ去っていて、
「すべてのデータ/オブジェクト/値に統一的な形で付与されるメタデータ」とでも呼べる使い方が広がってきていて、
実際そういうメタデータを活用することで実現された(&そういうのがないと作れない)便利なライブラリが、
この論文であったり一つ上の Bidirectionalization の話であったり、
その他 Haskell 方面全般、C++ なら Boost の諸々であったり。
これからもどんどんその方向にプログラミングの世界は発展していくと思うのですよ。
A. Warth "Experimenting with Programming Languages"
[PDF]
OMetaのひとのD論。
中身は、PEGベースの強力なパターンマッチの使える新しい言語である OMeta と、
実行時の環境(= 世界!)を分岐させたり合流させたりUndoしたり、
プログラミングの多世界解釈をできる Worlds という言語の2本立て。
どっちも OMeta/JS、Worlds/JS という JavaScript 拡張という形で使えるようになってます。
Worldsの方はまだちょっとどうなんだろ?と判断を保留したいところですが、OMeta
は便利。
正規表現なしで文字列処理をやれ、と言われると困る人は大勢いるとおもいますが、
それと全く同じで、
いざ存在を知ってしまうと、
OMetaくらい強力なパターンマッチなしでリストやツリーの処理をするなんてもう考えられないという気分になります。
D. Grune and C. Jacobs "Parsing Techniques - Second Edition"
[link]
実は5個思いつかなかったので論文じゃなくて本でお茶を濁します。
タイトルの通りひたすら構文解析の技法を解説しまくってくれる本です。
長らくの延期を経て2008年についに第2版が出版されました!
コンパイラや自然言語処理の本の一節としてちょこっと解説されることは多くても、
これだけしっかり構文解析だけにテーマを絞って書かれた書籍は他にありません。
LL(1) だの LALR(1) だの…についてももちろん載っているのですが、
「単一のアルゴリズムなのに、
一般の文脈自由文法ならO(n^3)、曖昧性のない文法ならO(n^2)、LR(*)の文法ならO(n)、
と、扱う文法の簡単さに応じて勝手にいい感じの計算量に落ちてくれる汎用パーザ」
だったり、
「構文解析と行列の掛け算の切っても切れない関係」
だったり、
「並列構文解析」
だったり、
「Chomskyの言語階層から外れるちょっとアウトローな文法達(PEGなど)」
だったり、
「文字列じゃなくてオートマトンに対して構文解析をしかける的なことをやって曖昧な入力や部分的な入力の構文解析」
だったり、
とにかく構文解析周りの話題が百花繚乱飛び回ります。これは楽しかった。
と、こんなところです。すでに一度ここで触れたものばかりですが、それは仕方のないことだと思う。
「2008年の(形式|プログラミング)言語系の話でこれが出てこないのはあり得ない!」等々つっこみあると思いますので、
ぜひぜひ、皆様のベスト5をお聞かせください。
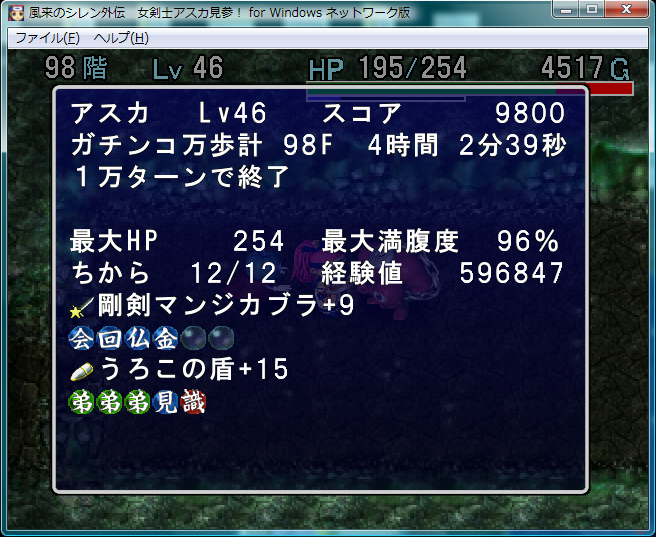 1万ターン経過すると強制ゲームオーバー、
というダンジョンだけクリア(100F到達)できずに残っているので最近再び挑戦してます。
昨日自己ベスト更新しました(左図)。やった。
1万ターン経過すると強制ゲームオーバー、
というダンジョンだけクリア(100F到達)できずに残っているので最近再び挑戦してます。
昨日自己ベスト更新しました(左図)。やった。
