{kind=link}
12:44 05/11/01
今日のショック
VMWare Player
微妙に話題に乗り遅れてますが VMWare Player を入れてみました。というか、qemu使えば全部ただで行けるよん、という記事を見かけて興味をもったので トライ。
動いた動いたー。マウスへの反応が異様に鈍いの以外は十分使えそうな速度で 動作しますね。このマウス何とかならないかなあ。
母上からの指摘で秋田県が赤くなりました。修正。 山形と茨城もこれでよかったか微妙に自信なし。 (追記:茨城も赤いことが判明。)
私の Tree Summing のコードが見たい人は、このページのソース内コメント 読んで下さい。「もっと読む」機能とか実装するの面倒なので手抜きばんざい。 あーでも、自分で解いてみて、できれば2日くらい悩んでみた人じゃないと 読んでも全然面白くないと思いますよん。
C言語の言語仕様の隅を突いてコードを短くする技能ってのは完璧に趣味の領域に 属すると思いますが、それとは別の「短く簡潔に書けるアルゴリズムを考える」能力の 方は、普段からわりと重要なのではないかという気もします。単純な話、コードの量が 少ないほど、バグの元も少ないわけで。例えば今回の問題を解くためだけに、自分 でTreeクラスを定義してそれを生成するparserを書いて…と延々と頑張って1KBの ソースを書いたりしていると、そこかしこでバグを出しそうです。
とか偉そうなことを言ってみましたが、まあ要はパズルだよね。
流行ってるらしいので 経県値。 ただし一部「泊まった」は「野宿した」を含みます。 奈良は修学旅行で泊まったかもしれない…覚えてないや。
あ、あんまりだった…。
もうムリ。マジ無理。forの初期化部が空だったり三項演算子の三項目に入れるものが
ないので適当に0が入ってたりとかなり無駄が多く見えるのですが、
潰し方不明。
もはや1Byteも縮められる気がしないのでやめようと思っていたのですけど、 抜かれるとなんか悔しいので、再挑戦。昨日までの方針では例外処理が 必要なデータが多すぎて手が出ないので、100%違うアルゴリズムにスイッチしました。 今度のはだいぶロバストです。昨日あげたデータや0 ()も全く厄介では なくなりました。
あとついに禁断のANSI C逸脱に手を染めてしまいました…。個人的制約として、普段 この手のに挑戦するときは、gcc -ansi -pedantic, cl /Za, bcc32 -A, dmc -A とそれぞれの最適化全開モードの計8通りでちゃんと動くことは 確認してるんですが、実は今submitしたコードはgccとbccに怒られてしまってます。 てか、そんなコードが書けるなんて今まで知らなかった。
追記:そして一瞬で抜き返されてる!
ちょwwみんな上位埋めすぎwww。
私の、間違ってるんだけどAcceptされてしまったプログラムを撃墜する例はこんなの。 このデータが嫌な理由がわかる人は私の採ったアルゴリズムもわかると思います。 少なくとも120Byte台の面々はほとんど同じ方法なんじゃないかと予想。
2 (1 (1 () (1()()))
(1 () (1()()))) /*パスは1+1+1=3しかないので正解はno*/
・ 型推論の紹介、「その説明なら高橋メソッドじゃないほうがわかりやすい」という 的確な突込みを各地からいただいております。そして実は自分でもそう思っているという。 記号多すぎ。次はもう少し工夫を考えてみるか…。
・ ご指摘の通りDAGやGraphのZipperは厄介な問題です。ListやTreeの例では ポインタをたどるときにそのたどったポインタを逆転すればよくて、やることが自明でした。 しかしDAGなどの場合はよくわからない。グラフ上でZipperを扱った研究でも、そのZipperは 基本ブロックを超えては動けない、みたいなのが多い気がします。というか、DAGやGraphの ような明示的にSharingを扱う構造を関数型で表現する方式自体、まだあんまり 完成されてないような感じが。(よく知らないのであやふや)
・ soreit(それいと)。 おおー。とりあえず第一感、名前が格好いい。うまいなあ。新たな言語を 作って実現すると、改造よりいろいろ自由にできて良さげ、というのは全く その通りですね。
「The Yakumo Project : 日本語ドキュメントを英語圏へ」
日本語圏内で流通している良いドキュメントやプログラムを英語に翻訳して、
もっと広く世界に伝えられるようにする専門のプロジェクトが必要なのではないか?
という提案。これは思いっきり同意します。自分も
Dのnewsgroup で "I see there is a lot of high quality D stuff on some
japanese sites... This is cool but why not in english?"
と言われてしまった
時に同じことを考えて、そんなことを書いてました。プロジェクト化するなら微力ながら
協力させていただきたいなあ、と意思表明しておきます。
tanakhさんの「コードを短くするのって楽しいですよね?」て話題。7行er的にはスルーできず挑戦。123Byteのは間違ってるんだけどAcceptされてしまった…。 修正すると126Byte。C++とiostreamで書くと184Byte。
int x = (scanf(...,&x) ? xを使った式 : ...);みたいなのと空白文字全削除以外は、妙な節約技は使ってない、つもり。
MLの型推論アルゴリズムを高橋メソッドで説明してみようとして、 よくわからんことになりました。SMLは+が微妙にオーバーロードされてるらしく 説明しにくそうなのでOCamlと限定しちゃってますが、SMLでもHaskellでもCleanでも 基本は同じです。mguの計算方法の説明がいい加減です。そしてこの勢いで let-polymorphism を説明できる気が全くしない。 間違ってるぞー、とか、ここがわからん、とかの突っ込みは大歓迎です。
※21:38 FireFoxで字のサイズがちゃんと変わるように修正。むずかしい。
「キョロ缶(P)」なる箱が来たので週明けに持って行きます>関係者 っていうかなんでウチに来るんじゃ。
Googleったら『サナギさん』の紹介ページに行き当たったのでリンク。サンプルとして公開されているの より面白いネタがもっと沢山あった気がするぞ…と思ってつい本屋に 行ってコミックを買ってきてしまいましたとさ。 …うん、「パンダに足りないモノ」とか「フクロウ先生」とかヤバい。 みんな読むべし。
Zipperの紹介をしてみる。考案者であるGérard Huet氏による最初の記事はWebでは残念ながら 読めない(※2011/08/01追記: 今は HaskellWiki から辿れる模様 )ですが、そっち系の図書館にでも行けば置いてあるはず…。先日書いたように、 純粋関数型言語でC++でいう Readable-Writable-Bidirectional イテレータに 近いものを実現するデータ構造です。要するに何ができるのかというと、 例えばリスト上のZipperならば、こういうもの。
let p = begin_of [1; 2; 3; 4; 5] in (* >1 2 3 4 5 *)
let p = next p in (* 1 >2 3 4 5 *)
let p = set 9 p in (* 1 >9 3 4 5 *)
let p = next (next p) in (* 1 9 3 >4 5 *)
let p = remove p in (* 1 9 3 >5 *)
let p = set (get p + 1) p in (* 1 9 3 >6 *)
let p = prev p in (* 1 9 >3 6 *)
let p = insert 0 p in (* 1 9 >0 3 6 *)
list_of p (* [1; 9; 0; 3; 6] *)
p が Zipper ね。副作用は一切使いません。遅延評価もしていません。最後のlist_of以外は 全て定数時間O(1)で実現されています(pは先頭からのインデックスをあらわす自然数とか いうショボいオチではありませぬ。)
例えばC言語なら、pはリストのノードへのポインタとすれば実現できるでしょう。
setはp->value = 9でいいし、removeはp->prev->next=p->nextみたいなよくあるポインタの繋ぎ替えでOK。ところが純粋関数型ゆえの悲しさ、
ポインタの指す先のデータを書き換えると言った副作用を使ったコードは書けません。
もうひとつ、OCamlにしろHaskellにしろLispにしろ、標準のリストは単方向リンクリスト
です。単純にリンクをたどるだけではprevに移動はできません。というわけで、一工夫必要です。
下のほうに実装は載せますが、自力で考えてみたい方はこの辺りでブラウザを置いて
挑戦してみて下さい。
というわけで、先にZipperの使い道の話でも。高階関数を使ったリスト操作は 関数型言語には充実している、こんな手続き型っぽいリスト操作方法は要らない、 という考え方もあろうかと思いますが…実際問題として、リスト上の"位置"を あらわすZipperのようなものは、無いとなかなか不便です。
例えば、条件を満たす最初の要素を探してきて返す関数のよくある実装は、 その要素そのものを返してくれます。(あー、コードはOCamlですが 別にOCamlに他意があるわけではなく、HaskellでもSchemeでも何でもいいです。)
(* ('a -> bool) -> 'a list -> 'a *)
let rec find pred = function [] -> raise Not_found
| h::t -> if pred h then h else find pred t
条件を満たす最初の要素を削除する関数は、別の関数です。
(* ('a -> bool) -> 'a list -> 'a list *)
let rec remove pred = function [] -> []
| h::t -> if pred h then t else h::remove pred t
条件を満たす要素まででリストを打ち切る関数や、それ以降のみを残す関数など、 全部別々に定義されているわけですが…これは、上の標準的なfindとは別の検索関数を 作ろうと思ったときに問題になってきます。例えば「条件を満たす最後の要素」 「を返す/を削除する/までで打ち切る/以降のみを残す」関数。あるいは、条件が 単独要素で決まらないような「先頭から足していって100を超える最初の要素」 「を返す/を削除する/までで打ち切る/以降のみを残す」関数。 「与えられた正規表現にマッチする部分リストの先頭」 「を返す/を削除する/までで打ち切る/以降のみを残す」関数。 このままでは、検索の種類nと操作の種類mに対してn×m個の関数が必要になってしまいます。
これをn+m個で収めるには、検索結果として要素そのものではなく、 検索にマッチしたリスト中の位置の情報を返す関数と
val find : ('a->bool) -> 'a list -> ???
val find_last : ('a->bool) -> 'a list -> ???
val find_over100 : 'a list -> ???
それに対する操作たち、
val get : ??? -> 'a
val remove : ??? -> 'a list
val before : ??? -> 'a list
val after : ??? -> 'a list
に分離されているべきです。お好みで高階関数にして
find_and_do 条件 操作関数 リスト
みたいなインターフェイスにするのもアリですが、どの道、"操作関数"に 渡す引数 ??? が必要なことに変わりはありません。というわけで、??? の実装の話に戻りましょう。
拍子抜けするくらいシンプルです。
type 'a list_zipper = 'a list * 'a list
(* 'a list -> 'a list_zipper *)
let begin_of lst = ([], lst)
(* 'a list_zipper -> boolとか'aとか'a list_zipperとか *)
let is_begin = function ([], _) -> true | _ -> false
let is_end = function (_, []) -> true | _ -> false
let next = function (l,e::r) -> (e::l,r) | _ -> raise Not_found
let prev = function (e::l,r) -> (l,e::r) | _ -> raise Not_found
let get = function (_,e::_) -> e | _ -> raise Not_found
let set e = function (l,_::r) -> (l,e::r) | _ -> raise Not_found
let insert e = fun (l, r) -> (l,e::r)
let remove = function (l,_::r) -> (l, r) | _ -> raise Not_found
(* 'a list_zipper -> 'a list *)
let list_of (l,r) = List.rev_append l r
begin_of と next の定義だけ見ればタネはわかると思います。
ペアの第一成分に、Zipperの指す位置より左の要素を逆順に積んで、第二成分には
右の要素をそのまんまの順番で置いてあります。別の言い方をすると、nextで
リストをたどるときは、逆方向に戻れるように一時的に逆向きのポインタを張っておく感じ。
ここまでリストで話をして来ましたが、要は最後に述べた、「リンクを辿る時は、 逆方向に戻れるように一時的に逆向きのポインタを張っておく」だけが肝です。 例えば二分木でも
type 'a bintree = BLeaf of 'a | BBranch of 'a bintree * 'a bintree
type 'a bt_path = Left of 'a bintree | Right of 'a bintree
type 'a bt_zipper = 'a bt_path list * 'a bintree
let root_of tr = ([], tr)
let down_left = function (p, BBranch(l,r)) -> (Right r::p, l) | ...
let down_right = function (p, BBranch(l,r)) -> ( Left l::p, r) | ...
let up = function ( Left l::p, r) -> (p, BBranch(l,r))
| (Right r::p, l) -> (p, BBranch(l,r)) | ...
...
こんな感じで木の中を上下左右うろうろできるZipperができあがります。 16日に私が書いたヤツは、子供の数が不定の木構造のZipper(ただし左に戻る必要は ないので左逆向きポインタは記録しない手抜き版)ですね。同じように考えると、 この手のポインタでつながってます系データ構造には全てZipperを定義することができます。 Generic Haskell は、データ構造の 定義から自動でZipper型と操作関数を構築してくれるようなGenericなライブラリが 記述できるのがウリらしいです。
でも結局、副作用や双方向リンクリストが普通の言語なら要らない? かというと…否。少なくとも知っておく価値はあるデータ構造です。 ZipperがポインタやC++/Javaのイテレータとは違う最大の点、欠点でもあり 利点でもある点に着目してみます。それは、同じリストに複数のイテレータから 書き込みができない点。
let p = begin_of [1; 2; 3; 4; 5] in
let q = p in
let p = next p in
let q = next (next q) in
let p = set 0 p in
let q = set 0 q in
list_of p; (* [1;0;3;4;5] *)
list_of q (* [1;2;0;4;5] *)
pで第二要素を0にして、qで第三要素を0にしてますが、これでは残念ながら [1;0;0;4;5] にはなってくれません。二行目の q = p がやることはポインタの コピーなのでその時点では両者は同じ実体を指しています。が、その後pやqから リストを操作すると、CopyOnWriteで、実体も別々のリストになります。 (実際はnextなどの操作でも別々になるのでCopyOnReadでもあるのですけど、 dirty flagでも入れておけばRead時には共有解除しないようには作れたりします。詳細略)
ただ、このCopyOnWriteはなかなか賢い。二つのZipperで全く手を加えていない部分、 この場合は末尾の[4;5]は、まだCopyされずに、二つのリストで共有されます。まとめると 「各要素ごとにポインタ1個だけのメモリ消費で、リストを双方向にたどれる」 「CopyOnWriteなので複製は一瞬」「CopyOnWriteの時も共通な部分構造については そのまま共有してくれる賢い」リスト構造ということになります。沢山コピーして 時々ちょびっと書き換えるようなリストの使い方をする時には、関数型リスト+Zipperは なかなか有望、かも。
Isabelleのロゴを 見るとどうしてもBeOSの実行可能ファイルの標準アイコンが思い出されてならない今日この頃です。 何か共通の由来があったりするのかな。
今マンガ雑誌を手にとって一番最初に読むお気に入りのマンガといえば、 ジャンプでは銀魂でありサンデーではからくりサーカスでありチャンピオンではサナギさんなわけですが。そんな中でヤングジャンプでの個人的トップバッターは、 『LIAR GAME』 なのであります。
― ある日突然届く1億円の札束。「これから30日間、いかなる手段を使っても構いません、 指定された対戦相手の1億円を奪ってください。30日後には元手の1億円を返してもらいます」 勝てば大金を手に。しかし負ければ1億の借金を負うことになる ― という、 どうしようもなく泥沼な設定で騙し合いの奪い合いに突入するお話が、ライアーゲーム1回戦。 現在はまた別のルールの騙し合い勝負となる2回戦が、クライマックスを迎えようとしている ところです。
で、こっから先は読んでない人を置いてけぼりにしますが、来週号で決着がつくはずの 2回戦にどうケリをつけてくるのか、さっぱり読めない。"15番"が実は主人公サイドと グルでした、くらいしか思いつかないけど、流石にそれはあんまりだし。うがー気になる 気になる。
最近他の人の記事に言及してばっかりですが、 samefringe problem (via Shiroさん) を考えてみます。自分なら、エセZipper的なものを使って…
type 'a tree = Leaf of 'a | Branch of 'a tree list
type 'a qzipper = 'a tree list list
(* 'a qzipper -> ('a * 'a qzipper) option *)
let rec next_leaf z = match z with
| (Leaf e::r)::c -> Some (e, r::c) (* == right *)
| (Branch e::_)::_ -> next_leaf (e::z) (* == next_leaf.down *)
| _::(_::r)::c -> next_leaf (r::c) (* == next_leaf.right.up *)
| _ -> None
あとは先頭から順に比較、かな。
(* 'a qzipper -> 'a qzipper -> bool *)
let rec same_z z1 z2 =
match next_leaf z1, next_leaf z2 with
| None , None -> true
| Some(e1,z1) , Some(e2,z2) -> e1=e2 && same_z z1 z2
| _ -> false
(* 'a tree -> 'a tree -> bool *)
let samefringe t1 t2 =
same_z [[t1]] [[t2]]
Shiroさんがいくつか挙げておられた解と本質的には同等です。木の深さに比例する 空間が必要。
Zipperというのは誤解をおそれずに言うと、純粋 関数型言語でC++でいう Readable-Writable-Bidirectional イテレータに 近いものを実現するデータ構造で、わりとすごく便利。
Binary2.0カンファレンス 2005 だそうな。大雑把に言うと機械語の実行コード列を データとしてうにうに弄って遊んじゃう話、っていう感じでしょうか。自分ではその手の ことは必要最低限しかやったことがないのですけど、shinichiro.hさんの顔を見に、 じゃなかった、普通に面白そうなので参加登録してみました。
この前自分用に作った、実行中の他プロセスに潜り込んで勝手にWow64DisableWow64FsRedirectionして帰ってくるアプリとかは
多少近いんですかね。でも、ただAPI呼んでるだけだしなあ。
(32bit版しか提供されていないランチャから、64bitのnotepad.exeやcmd.exeを起動させる
ためにやりました。今考えると、一枚ラッパさえ噛ませればすんだような気が…まいっか)
tomozo.ne.jp って消えてる?
結城さんから、Knuth先生の文芸的プログラミングツールに長いセクション名の省略という機能があることを教えていただきました。 長い名前を毎回使うのは面倒だから、一意にわかるくらいの情報さえ あれば残りは省略してもいいよ、というスタンスはかなりの関係ありですね。
あと、メソッド名推論をさせていることを明示的に示す記号を入れるとしたら、
... はいいかもしれない、などと思いました。
wnd...(new MouseListener(){}) みたいな。あれ、やっぱり変かも。
Noahのインストーラにウイルス検出と出るよん という連絡をPCNOMさんにいただきました。リンク先の記事に書かれていた VirusTotal というサイト (ファイルをuploadすると20種類くらいのウイルススキャナをかけてくれる。 ここ今まで知らなかったんですが便利ですね)いわく、AVGとVBA32で検出される模様。 他のでは全てno virus foundになります。Noahのに限らずgcaで作った自己解凍書庫を 投げると全部同じ結果ですね。
特に変な挙動も見えませんしたぶん誤検出でしょうけど、気になる方はzip書庫の方を ダウンロードしてください。あるいは、インストーラ版の方でも何かgcaを展開できる ソフトに渡せば実行せずに展開できます。
PCNOMさんの「せめて、誤検出報告のわかりやすい窓口をベンダー各位には用意して
もらいたいと思います。
」には同意ですね。っていうか、これ、どうすればいいんだろ。
水島さんから
指摘いただいた「showMessageDialog(...) という呼び出しは
showMessageDialog(Component,Object) と
showInternalMessageDialog(Component,Object) の両方に
マッチするので、前者を絶対に呼び出せなくなってしまっている」、というのは
なんとかしないとマズいところ。妥当な解決策は「引数の型が合うexact matchは優先」
というルールにすることですかね。「引数の型の適合度」という順序と
「名前片集合の適合度」という順序の二つがクロスすることになるので、
ちと複雑になっちゃいました。
IDEの補完機能として実装というアイデアは、確か某NanDEMOの時に他の人からも いただいたのですが、自分としてはそれだと不満かなあ、と思っています。 「MouseListenerと2回も書く必要がなくなって楽」にはなるのですが、 「MouseListenerと2回も読む手間」が以前と変わらないので。もっとも、 最近のIDEによくあるコード折りたたみ機能の延長で、長いメソッド名を勝手に横に 折りたたんで表示するという方向まで考えれば、「読む手間」の削減にもなりそうです。
発展させて激しくやり過ぎるとわかりにくくなるよね、っていう各所での反応は その通りかと。個人的には、データの流れと逆方向の推論(後での返値の使われ方の 情報を使って実際に呼び出す関数を決める、とか、関数の定義内での使われ方を見て 引数の型を決める、とか)は避けた方がよいと考えています。でもまあ、 データの流れと同じ方向の推論であれば、それなりに人間把握できるような。
プリプロセサとして 作らなかったのは、使い勝手はひとまず置いて作る手間だけ考えると、圧倒的に コンパイラを直に弄った方が楽だから、ですね。Nikesの場合だとプリプロセサとして 作るなら「1.字句構文解析→2.意味解析→3.名前推論→4.ソーステキストに戻す」を全て 実装しないといけないですが、1.と2.はどうせ既存のコンパイラから拝借することに なるでしょうし、4.はコンパイラに組み込めば不要なステップ。 でも利用するコンパイラのマイナーバージョンアップへの対応なんかを考えると、 プリプロセサにしておいた方が便利なんですが。
Muzieで知った『月杜の祭』が最近ヘビーローテ中。みんなのうたで新曲が流れているらしいのだけど、 どこかWebで試聴できないものでしょか。。。
Nikes - A Java Compiler with Name Inference。 今日の記事はめっさ長いですスミマセン。
プログラミング言語の機能として「名前推論」 ……と自分では 呼んでいるけれどいまいちなネーミングだとは思う……あんまり推論してないし…… が欲しいと常々思っていまして、proof of concept ちうことで実装してみました。 ソース公開されているマトモなコンパイラの中で一番弄りやすそうだった Jikes のちょこっと改造品です。Java2 1.4 の全機能に 加えて、以下の3つの機能が追加されてます。
例えば
public class Sample {
public static void main( String[] args ) {
String msg = "Hello, world.";
System.out.println( msg );
}
}
の代わりに
public class Sample {
public static void main( String[] args ) {
String msg = "Hello, world.";
System.out.println( String );
}
}こうクラス名を書けるようにしたものです。スコープ内にそのクラスの変数が 1個だけあったら、その変数名を書いたのと同じ動作をします。2個以上あったら、 あいまいなのでエラーです。
それのどこが嬉しいんだ?つーかタイプ量増えとるやん、という意見は あると思います。これついては後で。要は「全部の変数に名前付けて 回らなきゃいけないのは面倒くさい、あるいは、無駄に名前を使いすぎるとかえって わかりにくくなるプログラムもあると思う」と前々から思っているので、それの実現。
こちらは例えば
wnd.addMouseListener( new MouseListener(){ ... } )
の代わりに
wnd.add( new MouseListener(){ ... } )
とメソッド名の一部だけ指定したら、引数が MouseListener クラスであるという情報を使って、 適切なメソッドを決定して呼び出すものです。これは要するに二回もMouseListenerと 書くのも見るものめんどい、と、まあそれだけの理由です。 ものぐさ人間としては、自明な場合にはメソッド名なんか書いてられるかってことで
wnd.( new MouseListener(){ ... } )
こう書きたいのですが、これは改造が少し手間なので
wnd._( new MouseListener(){ ... } )
こう書くとメソッド名のヒントをひとつも与えずに型情報だけからメソッドを決定します。 ただしJavaのクラスライブラリの設計的に、ノーヒント推論は大抵あいまいエラーで失敗 するような印象。
特に面白いことは何もないのですが、作るのはメチャ楽なので、D言語やC++0xのautoやら C# 3.0のvarのような、変数の型を宣言時の初期化子から暗黙に決定するあれも勢いで追加。
var msg = "Hello, World."; //String型
var pi = 3.141592; // double型
var n = 100; // int型
var wnd = new JFrame(); // JFrame型
var x = new int[] { 1, 2, 3 }; // int[] 型
ここからもーちょい具体的に、それぞれについて説明します。まず変数名推論について。 自分の中では割と自明に嬉しい機能なのですけど、いちいち全部のローカル変数を名前で 呼ぶのは嫌いでクラス名で呼びたい、というのはあんまり共感されたことがないので、 もう少し屁理屈を練ってみるテスト。
日本語や英語など、自然言語で考えてみる。ある具体的な"もの"について話すときに、 あなたはいちいちその"もの"に固有名をつけるでしょうか? 否。暑いので部屋に風を入れて 欲しいときに、「窓を開けてくれ」 とは言いますが、全ての窓に名前がついていて 「窓太郎を開けてくれ」と言ったりは普通しません。
これは固有名で指さないで一般名詞の"窓"を使っても、その文脈で"窓"といえばどの"窓"の ことか、わかるからです。他の色々な会話を想像してもらえばわかると思いますが、窓に 限らず多くの場合私達は、ものにいちいち名前をつけずに一般名詞で呼んで、文脈から 具体的に指すものを決定しています。むしろ逆に、すべてのものに名前をつけてまわるのは、 つけるのも面倒、覚えるのも面倒でやってられません。
同じことはプログラミング言語でも言えると思うのです。文脈でわかるもの全てに 名前をつけるのは面倒だし覚えるのも面倒だしそもそもわかりにくいのではないか。
Window = new Window();
String = LoadStringFromResource(ID_XXX);
Window.SetTitle(String);
Window.Show();
"Create a new window. And load a string from resource. Set the string as the title of the window. Then show the window." いくつかは代名詞itなどで置き換えられる かもしれないけれどそれはともかく、自然にしゃべるのであれば決して "Create a new window WND. And load a string TITLE_STR from resource. Set TITLE_STR as the title of WND. Then show WND." とは言わない。
変数名推論が一般名詞を使って固有の物を指す、いわば "the" だとすれば、 Perlの"$_"やなでしこの"それ"のような代名詞 "it" も、近いものとして既に あります。が、全て代名詞だけで文章やプログラムを書くのは、ちょっと苦しい。 固有名と$_の狭間として、型/クラスの名前を使ってみる、というのが この辺りとの違い。
もちろん、自然言語でもプログラミング言語でも、名前をつける必要があることも 多々あります。その時は従来通り、変数に名前をつけて区別するとよいでしょう。 ただ、必ずしも全ての変数を名前で参照しなくてもよいのではないかなー、という ことでした。
※ 本文中の、変数宣言時に変数名を省略する書き方 (String = Load...)
は今のNikesだとまだ出来ません。パーザ弄るのが面倒だったので…(^^;
JikesはまだGenericsを実装していないのでNikesでも試せないのですが、 思考実験ということで。思考実験なので例がいきなりC++になります。 C++標準ライブラリのset::insertメソッドの一つは、
pair<iterator,bool> insert( const value_type& x );
挿入された要素を指すiteratorと、今回新しく挿入できたのかそれとも既に入ってた 要素なのかを表すboolのペアを返します。型を見ればわかるように、ペアの第一要素が iteratorの方で第二要素がboolの方なので、例えば挿入位置のiteratorを使ってその後で 何か処理をしたければ
result = set.insert(val);
... result.first ...;のようにresult.firstを使ってアクセスします。これはpairのフィールド名が
template<typename A, typename B> struct pair {
A first;
B second;
};こんな感じの名前で定義されていて、第一成分にはfirstでアクセスすることに なってるからなのですが、ここで問題が発生します。名づけて「どっちがfirstで どっちがsecondだったっけproblem」。「iteratorの方を使いたいのだけど、 ドキュメントを見ないとfirstがiteratorなのかsecondがiteratorなのかわからない」 という状況です。別にset::insertに限らず、C++でpairを使ったことのある人や、他の 言語でもtupleを使ったことがある人は必ず遭遇したことがある状況だと思います。 実際、「pairやtupleは型をgenericに出来ても名前をgenericにできなくてプログラムが わかりにくくなるので、結局pairを使わずに毎回それぞれ別の構造体を作るようになった」 という体験談を何人もの人から聞いたことがあります。
変数名推論を使ってみましょう。
result = set.insert(val);
... result.iterator ...;resultのメンバ変数はiterator型のfirstとbool型のsecondです。iteratorという 型名を与えられたら、first側であることが自動的にコンパイラに伝わります。ばんざい。
コンパイラってものは、大まかにわけると 「字句構文解析 → 意味解析 → 最適化 → コード生成」 というフェーズに分かれています。変数名推論は、普通なら型名を意味するはずの 識別子に変数を指させるだけのものなので、"意味解析"部分さえ書き換えれば 後段の最適化やコード生成部分には何も手を加える必要はありません。
普通なら文法上は型名は来られないはずの位置に型を書けるようにする文法の 変更なので、構文解析フェーズには手を加える必要があるかと思いきや…実は、 とりあえずレベルの実装ならば、構文解析部も変更は要りません。 意味解析部だけ微妙にいじれば改造できます。
というのは、JavaやC++などの処理系では、yaccなどのツールで扱える LALR(1) 文法に落とすために、実装上は文法の段階では変数名と型名を区別せず、ただの "名前" としてまとめて扱って意味解析フェーズに渡しています(Java言語規定 19)。つまり元々意味解析に入ってくる段階では 変数名と型名はごっちゃになっているので、そこで二者を区別するコードに 手を加えれば、改造完了です。
というわけでC++コンパイラやDコンパイラを改造して変数名推論を加えるのも そんなに難しくないはず…なのですが、一点だけ落とし穴が。int や boolean などなどのプリミティブ型の型名達は、"予約語" として 字句解析レベルで既に変数名とは区別されちゃってます。これらに対しても 変数名推論可能にしたいと思った場合は、字句解析か構文解析にも手を加える 必要がありそうです。(現在のNikesの実装はこれをやってません。)
まじめに構文解析から修正(変数宣言を省略できるようにする。プリミティブ型でも 推論できるようにする)。gdc辺りでも実装してみる。"the"を意味する、変数名推論で あることを意味する記号を明示的に書けた方がいいかどうか考える。…etc
元々は、wnd.( ... ) のように、メソッド名全省略しても引数オブジェクトの型から 適用すべき処理を判別して欲しい、という機能だけを考えていました。机上の空論的話から いくと、"selfオブジェクト" と "関数名/メッセージ名/タグ/ラベル" と "引数オブジェクト" の3つを合わせると初めて何らかの処理が発動する、というメカニズムは なんか対称的でなくて格好悪い気がしたのです。オブジェクトとオブジェクトを何個か "寄せ集め"たら、そこから自動的に処理が発動するっていう仕組みでよくない?と。 配列オブジェクトaと整数オブジェクトiを持ってきてやりたいことと言ったら、 aのi番目の要素を取ってきたいのに決まってるだろう、と。
a.getAt(i)とか冗長なこと書かずに、
a.(i)でいいじゃん、と。勿論オブジェクトを複数個集めたときにやりたい処理が常に一意に定まる とは限らないので、複数の選択肢から選択するためのselectorとして、"名前"として以外に 意味を持たないオブジェクトをヒントに絡ませるのはありでしょう。本当はaのi番目の要素を 削除したかったんです、という意図を伝えるために、
a.(:remove, i)と書けることは重要だと思う…云々かんぬん。
が、まあ考えてみるとわかりますが、本当に型だけからやりたい処理が完全に推測できる例は そこまで多くない。それで結局いつもselectorとして名前が必要になるのだったら、 元と何も変わらないわけです。 などというようなことを、このページの "一つ未来のページ ≫" にひっそりとメモって いたことがありました。
で、今は亡きその記事にいつの間にか Onion開発日記 で言及されていて、そこで「メソッド名の一部を指定する」という案が 書かれているのを見て再度考えました。これは別の問題として昔から気になっていた 「doHogeとDoHogeとdo_hogeを区別するのは理不尽だと思う問題」と、「テンプレートと接尾辞、名前空間と接頭辞の互換性問題」 とまとめて考えるべき問題なのではなかろうか。
YTさんが指摘されている ように、"doHoge" と "do_hoge" は同一視するとしても、更にこれらと "doh_oge" をも 同じ物として扱ってしまうのには、なるほど問題があります。前二者は、"do" と "hoge" を区切る目的でHを大文字化したり、あるいは下線を挟み込んだりしているわけで、この 意図は保ったほうがよさげです。
逆に言うと、Java風にしろC++風にしろ現在のよくある命名規約は、区切り子の違い こそあれ、どれも名前を単語のリストとして与えるように作られている、と。doHoge や do_hoge という名前が意味しているのは、[do, hoge] というリスト。名前 = 名前片のリスト。 そしてそれ以上のことは意味していないはず。
[add, mouse, listener] であれば、何かを追加するメソッドであり、マウスに関連する 何かであり、Listenerに関連する何かである、という3つの情報でもってメソッドの名前と なっていると考えられます。(ついでに、名前空間名や、テンプレートやGenericsの引数も、 メソッドを特定するための情報の一片と考えられると思うのでこの辺りもいずれ統合 したい…けれど今回は略。)名前空間やテンプレート引数が必要に応じて適宜省略できるのと 同様に、名前片の一部も、他の情報から推論できるなら、適宜省略できるようにしてしまえい!
ということで、メソッド呼び出し時はメソッドのフルネームではなく、名前片の集合を適当に
与えることで呼び出せるようにしてみました、というもの。wnd.add(...),
wnd.mouse(...), wnd.add_listener,
wnd.MouseListener(...) などなど、色々な呼び出し方が可能です。
※ YTさんの記事に関連させてみると、現在の Nikes は DoHoge = doHoge = do_hoge ≠ doh_oge = Doh_Oge です。 ただしさらに、内部実装がsetなので、 do_hoge = hoge_do = hoge_do_do = do_hoge_hoge_do です。 これを順番や個数は重視するように変えるべきかは考え中…。
「名前推論」というネーミングは「型推論」 を意識しています。で、その意識した型推論ってやつが、自分はあんまり 好きではないんです。今回C.で作ったような、変数の初期値から変数の型を 推論するのはまだいい。けれど、関数の定義から関数引数の型を推論する方向の 型推論は、不要だと思うのですよ。だって
(* list.ml *)
let find p l = ...という関数名や引数名の宣言を見るよりも、
('a -> bool) -> 'a list -> 'a型を見たほうがよっぽど何をする関数なのかわかりやすいですし。 人間に前者を書かせて、前者から後者を処理系が推論するのが型推論ですが、 型推論を期待したせいで後者(型情報)が書かれていないソースは、あまり 読みたいものではないです。
むしろ後者から前者を推論して欲しい…ってそれは流石にムリですが、でも、 人間が手で書いた関数定義が幾つかあったときに、型情報を与えるとそれに 合致した関数をとってきてくれる機能があった方が、型推論よりもよっぽど 嬉しいと思います。ということでメソッド名推論なのでした。
変数名推論同様、とりあえずで実装するなら、意味解析以外のフェーズに 手を加える必要はありません。
メソッド/関数の多重定義(オーバーロード)が既にできる言語ならば、メソッド名推論を 実装するのも簡単です。普通のオーバーロードは、指定されたメソッド名と完全マッチする メソッドを全てとってきて、あとは言語の定義に従って、そのメソッド集合の中から型が 最も適切なものを選んでくるという形で実装されています。
メソッド名推論の場合は、指定されたメソッド名を名前片の集まりに分解して、それと 部分マッチするメソッドを全てとってきます。あとはそのメソッド集合を、普通の オーバーロードのときの最適メソッド選択ルーチンにそのまま投げるだけ。
まじめに構文解析から修正(完全メソッド名省略構文)。名前片への分割アルゴリズムは 大いに考慮の余地あり。名前空間を限定するstd::やjava.util.のような指示も、 テンプレート/Genericsの引数として与える型名も、全て他の名前片と同様に扱うことは 可能か?(std::vector<double> = std_vector_double = StdVectorDouble) … etc。
変数名より型名の方が長いのでタイプが面倒になるという欠点は、IDEなりdabbrevなりの 助けを借りればどうにでもなる、はず。あるいは親クラスのクラス名を使って子クラスの 変数を推論してもかまわないので、
catch( NullPointerException ) {
Logger.print( Exception.toString() );
}適度に親の方の名前を使えば名前もそんなに長くないのでは、とか。この場合でも NullPointerException固有のメソッドとかも普通に呼べます。 そもそもあくまで"推論"なので、いつでも従来通りの人間による変数名の 明示指定もできるわけで、型名で書く方が面倒なときは変数名を使うべきでしょう。
ハンガリアン記法と違うのは、変数を型の名前で"名づける"のではないところ。
関係あるようなないような、多分ない参考資料1: 「プログラマは名前を付けるのに慣れすぎている」というのは意外と認識されていないかも
関係あるようなないような、多分ない参考資料2: Method Finder というのがあるらしい。ここまでの私の議論は全部静的型づけ言語を前提としてましたが、 動的型にするとどうすればよいのか…というのはなかなか難しい。参考にすべきかも しれない。やっぱり違うかもしれない。
ノカ って象っぽくありません? ノカ <パオーン
2ヶ月前に作ったけど説明文書くのが面倒で放置してあった小ネタを、 関係あるようなないような気がするので、YTさんの識別子の一致規則という記事が出たのを機に晒してみようと文章書きはじめました。 のですけど、時間切れで間に合わなかったのでまた明後日に。
てなわけでちょっと 八王子 行ってきます。今年は選手じゃないので気楽なもんですね。
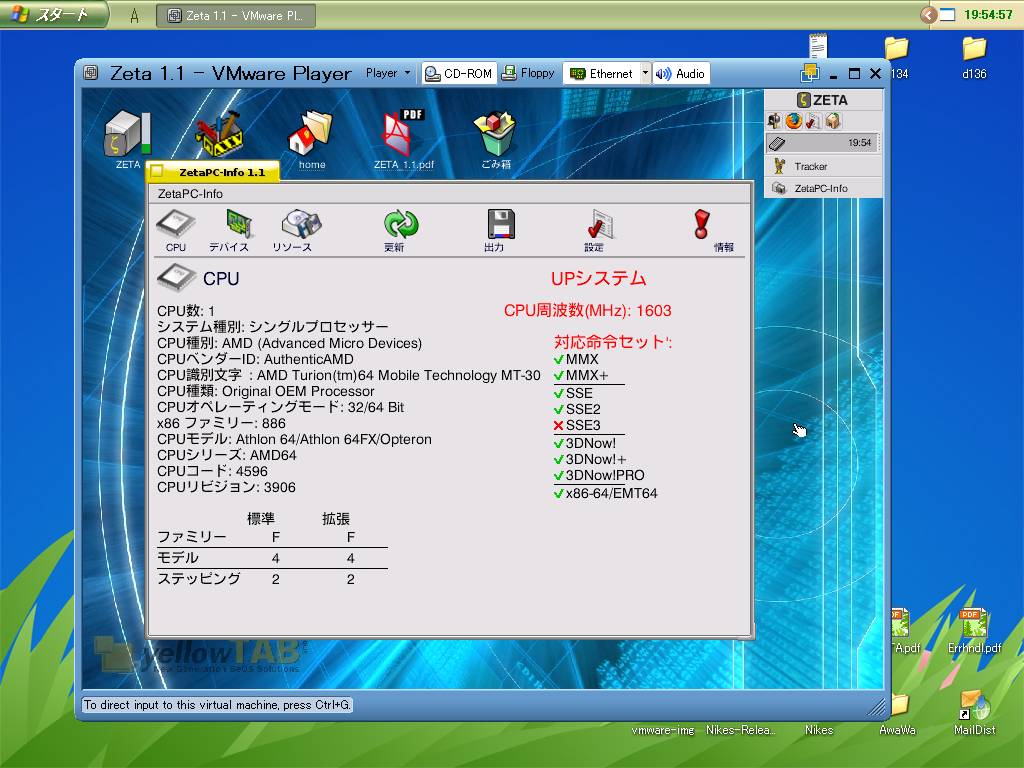
微妙に話題に乗り遅れてますが VMWare Player を入れてみました。というか、qemu使えば全部ただで行けるよん、という記事を見かけて興味をもったので トライ。
動いた動いたー。マウスへの反応が異様に鈍いの以外は十分使えそうな速度で 動作しますね。このマウス何とかならないかなあ。
不安定という噂を聞いたのでしばらく控えてた Zeta 1.1 へのアップデートを今日敢行。 サウンドカードのドライバ周りの更新がもろに自分の環境を改善してくれそうなので、 やっぱり入れることにしました。アップデートしたら解像度が1024*768*16bppしか 選べなくなってちと焦りましたが、VESAの設定ファイルを 消せというアドバイスを見つけたので試したところ無事復旧。他には何事もなく順調に動いてます。 Tracker Add-onのThumbnailerが復帰したのが嬉しい。
Zeta OS未体験の方も、最近 LiveCD体験版 が無料公開されたそうなのでぜひぜひお試しあれー。
あーほんとだDPだorz
long long eight_princes(long long N) {
if( N<=16 )
return 0;
if( N%2==1 )
return N*(N-9)*(N-10)*(N-11)*(N-12)*(N-13)*(N-14)*(N-15);
enum {VV, OV, VO}; // Vacant, Occupied
long long dp[2][9][3] = {0};
dp[0][1][OV] = 1;
for(int i=1; i<=N/2-1; ++i)
for(int j=1; j<=8; ++j)
dp[i&1][j][VV] = dp[i-1&1][j][VV]+dp[i-1&1][j][OV]+dp[i-1&1][j][VO],
dp[i&1][j][OV] = dp[i-1&1][j-1][VV]+dp[i-1&1][j-1][VO],
dp[i&1][j][VO] = dp[i-1&1][j-1][VV]+dp[i-1&1][j-1][OV];
return (dp[N/2-1&1][8][VV]+dp[N/2-1&1][8][VO])*N*5040;
}
